Outils Dentaires Automatisés avec l'Apprentissage Profond
Pendant un an, j'ai travaillé pour l'école dentaire de l'Université du Michigan, Ann Arbor, aux États-Unis. Le département d'orthodontie et de dentisterie pédiatrique dispose d'un groupe de recherche composé d'informaticiens et d'orthodontistes. Le laboratoire collabore avec les Neuro Image Research and Analysis Laboratories (NIRAL) en Caroline du Nord ainsi qu'avec Kitware, Inc., une entreprise spécialisée dans la recherche et le développement de logiciels open source dans les domaines de la vision par ordinateur, de l'imagerie médicale, de la visualisation, de la publication de données 3D et du développement de logiciels techniques. Au cours de ce stage, j'ai développé et mis en œuvre deux outils d'apprentissage automatique (ALICBCT et AMASSS) pour aider les cliniciens experts dans le diagnostic, le traitement et la recherche sur les scans crânio-faciaux des patients. Les outils développés sont maintenant déployés sur deux écosystèmes open source disponibles gratuitement pour tous : le Smart-DOC, un système basé sur le web, et sur 3D Slicer, un logiciel open source d'analyse d'images et de visualisation scientifique. Cela a été possible grâce à une collaboration de centres cliniques du monde entier. Grâce à des efforts communs et à une collaboration, nous avons déjà développé quatre outils d'apprentissage automatique prêts à être utilisés sur le module Slicer Automated Dental Tools.
J'ai publié un article en tant que premier auteur sur chacun des outils suivants : AMASSS et ALICBCT
Mon profil Google Scholar : Maxime Gillot
J'ai également écrit un book chapter décrivant le travail de notre équipe.
AMASSS
Publication dans PLOS ONE : Automatic multi-anatomical skull structure segmentation of cone-beam computed tomography scans using 3D UNETR
AMASSS signifie Segmentation Automatique de la Structure Crânienne Multi-Anatomique. Dans ce cas, la segmentation des scans CBCT. La segmentation des images médicales et dentaires est une tâche visuelle visant à identifier les voxels des organes ou des lésions à partir des scans de niveaux de gris de l'arrière-plan.
Cela représente une condition préalable à l'analyse d'images médicales. Particulièrement pour des conditions dentaires et craniofaciales difficiles, telles que les déformations dentofaciales, les anomalies craniofaciales et l'impact des dents, l'analyse quantitative d'images nécessite des solutions efficaces pour résoudre la tâche chronophage et dépendante de l'utilisateur de la segmentation d'images.
Les images CBCT à grand champ de vision couramment utilisées pour les applications cliniques en orthodontie et en chirurgie maxillofaciale nécessitent en moyenne des segmentation détaillées par des cliniciens expérimentés : 7 heures de travail pour l'ensemble du visage, 1,5 heure pour la mandibule, 2 heures pour le maxillaire, 2 heures pour la base du crâne (CB), 1 heure pour les vertèbres cervicales (CV) et 30 minutes pour la peau.
L'entraînement des modèles d'apprentissage automatique a permis de segmenter les scans CBCT en moins de 5 minutes avec une grande précision.

ALICBCT
Publication : Identification automatique des repères dans la tomographie par faisceau conique
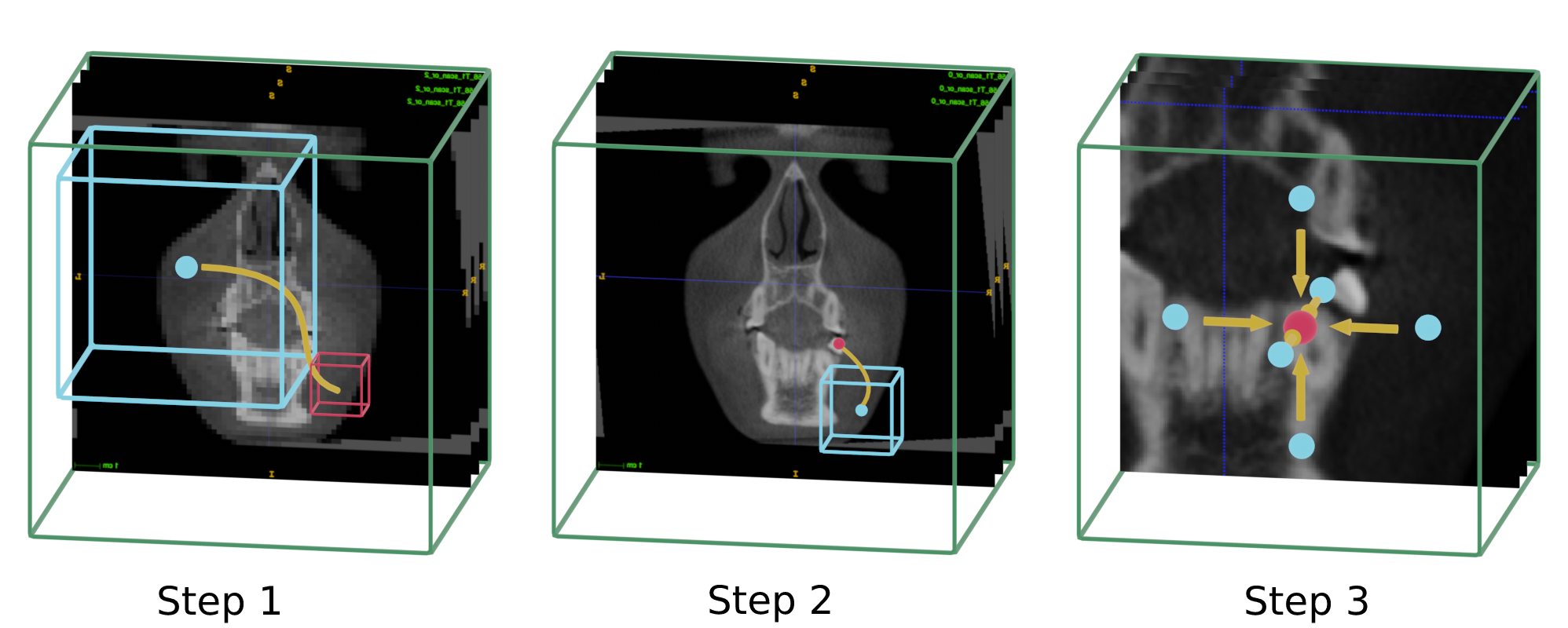
ALICBCT signifie Identification Automatique des Repères dans les scans CBCT. La localisation précise des repères anatomiques pour les données d'imagerie médicale est un problème difficile en raison de la fréquente ambiguïté de leur apparence et de la grande variabilité des structures anatomiques. La détection de repères représente une condition préalable à l'analyse d'images médicales. Elle soutient l'ensemble des processus cliniques, du diagnostic à la planification du traitement, de l'intervention au suivi des changements anatomiques ou des conditions pathologiques, ainsi que des simulations. Dans ce travail, nous avons présenté une nouvelle méthode inspirée d'une technique d'apprentissage par renforcement profond. La tâche de détection de repères est configurée comme un problème de classification du comportement pour un agent artificiel qui se déplace dans la grille de voxels de l'image à différentes résolutions spatiales.
Présentaton des différents outils au Moyers symposium 2022
Book chapter
L'agent virtuel dispose d'un champ de vision en forme de boîte autour de son point central. Il analyse ce dernier à chaque itération pour déterminer la prochaine direction dans laquelle il doit se déplacer. En répétant ces étapes jusqu'à ce que l'agent cesse de se déplacer, nous atteignons finalement la zone du repère souhaité. Nous effectuons ce processus à deux résolutions différentes : d'abord à une résolution plus basse pour se déplacer rapidement et approximer l'emplacement, puis à une résolution plus élevée pour déterminer précisément l'emplacement du repère.
Petite vidéo de présentation du projet ALI-IOS :