automated dental tools using Deep learning
During one year I've been working for the dentistry school of the University of Michigan , Ann Arbor, USA. The Department of Orthodontics and Pediatric Dentistry has a research group composed of computer scientist and orthodontists. The laboratory is working in collaboration with the Neuro Image Research and Analysis Laboratories (NIRAL) in North Carolina as well as Kitware .inc, a company specialized in the research and development of open-source software in the fields of computer vision, medical imaging, visualization, 3D data publishing, and technical software development. During this internship I developed and the implemented two machine learning tools (ALICBCT and AMASSS) to assist expert clinicians in the diagnosis, treatments and research on patients cranio-facial scans. The developed tools are now deployed on two open-source ecosystem available for free to anyone: the Smart-DOC, a web based system, and on 3D Slicer, an open source software package for image analysis and scientific visualization. This was possible thanks to a collaboration of clinician centers from all over the world Through common effort and collaboration, we have already developed four machine learning tools ready to be used on the Slicer Automated Dental Tools module.
I published a papers as a first author on each of the following tools : AMASSS and ALICBCT
They are available on my Google scholar profile : Maxime Gillot
I also wrote a book chapter decribing our team's work.
AMASSS
Publicaton at PLOS ONE : Automatic multi-anatomical skull structure segmentation of cone-beam computed tomography scans using 3D UNETR
AMASSS stands for Automatic multi anatomical skull structure segmentation. In this case, the segmentation of CBCT scans. Segmentation of medical and dental images is a visual task that aims to identify the voxels of organs or lesions from background grey-level scans.
It represents a prerequisite for medical image analysis. Particularly for challenging dental and craniofacial conditions, such as dentofacial deformities, craniofacial anomalies, and tooth impaction, quantitative image analysis requires efficient solutions to solve the time-consuming and user-dependent task of image segmentation.
The large field of view CBCT images commonly used for Orthodontics and Oral Maxillofacial Surgery clinical applications require on average to perform detailed segmentation by experienced clinicians: 7 hours of work for full face, 1.5h for the mandible, 2h for the maxilla, 2h for the cranial base (CB), 1h for the cervical vertebra (CV), and 30min for the skin.
The training of the machine learning models allowed to segment the CBCT scans in less than 5 minutes with great accuracy.

ALICBCT
Publication : Automatic landmark identification in cone-beam computed tomography
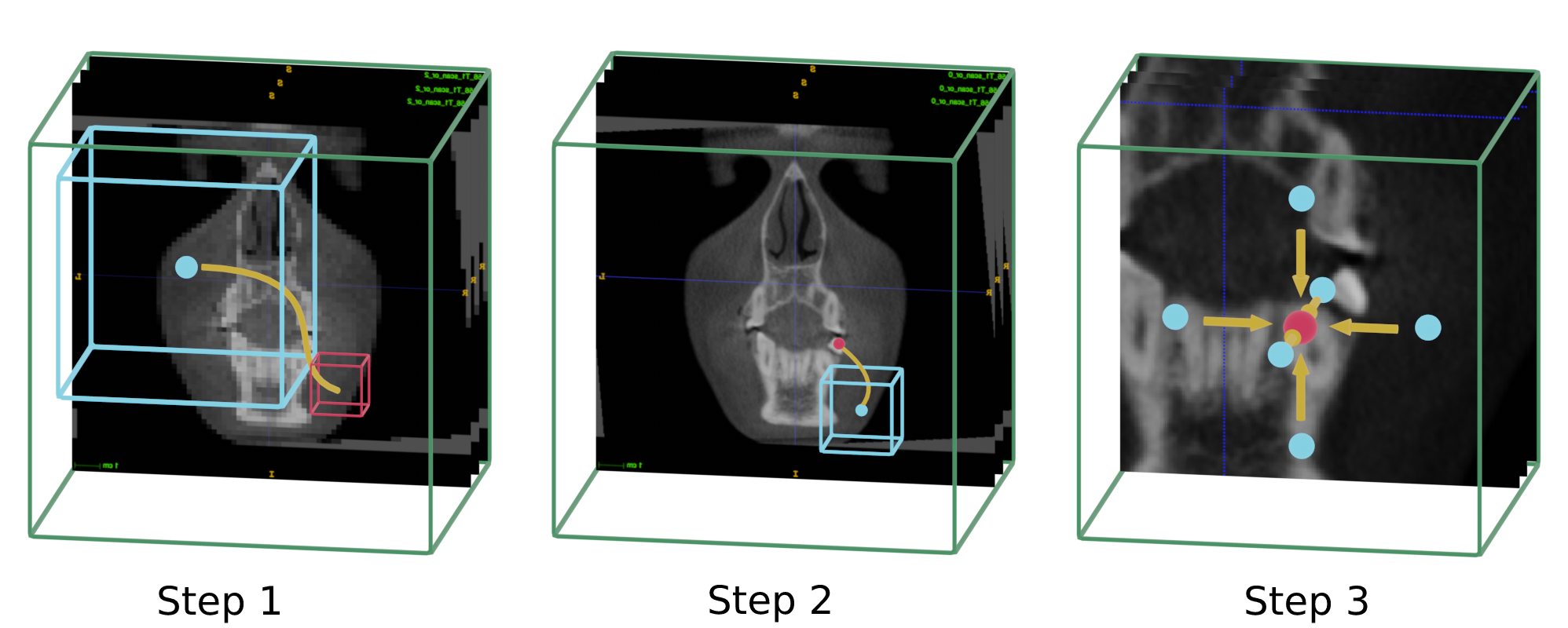
ALICBCT stand for Automatic landmark identification in CBCT scans. The accurate anatomical landmark localization for medical imaging data is a challenging problem due to the frequent ambiguity of their appearance and the rich variability of the anatomical structures. Landmark detection represents a prerequisite for medical image analysis. It supports entire clinical workflows from diagnosis, treatment planning, intervention, follow-up of anatomical changes, or disease conditions, and simulations. In this work, we presented a new method inspired by a deep reinforcement learning technique. The landmark detection task is set up as a behavior classification problem for an artificial agent that navigates through the voxel grid of the image at different spatial resolutions.
Presentation of all the developed tools at Moyers symposium 2022
Book chapter
The virtual agent has a box-shaped field of view around its center point, which it analyzes at every iteration to determine the next direction in which it should move. By repeating these steps until the agent stops moving, we eventually reach the area of the desired landmark. We perform this process at two different resolutions: first at a lower resolution to move quickly and approximate the location, and then at a higher resolution to precisely pinpoint the landmark's location.
An other video to present how the ALI-IOS project works :